

The following is a transcript of the presentation video, edited for clarity.
We’re now moving to the Approach and Preliminary Studies section.

We’ve talked a great deal about this idea that projects have to be high in significance and high in innovation.
But all is lost when an approach is not feasible or does not lead to data that will accomplish the aims of the project. I think we all understand that.
The statistical plan is crucial for assessing the likelihood that the project will yield interpretable results. In the Summary Statement, it’s my experience and I expect the experience of others in this room, that the Approach generally receives the most attention.
Take a great deal of care with this section. As with every other section, obviously.
Considerations and Common Weaknesses

Everybody has mentioned that it would benefit you to read what the reviewer is supposed to attend to during the reviews. For every mechanism, this is accessible online. For every mechanism — F-awards, Rs — the reviewer has questions they are supposed to attend to as they fill out the critique.
For all grants, the question is: Does the research plan address scientific significance, originality, and feasibility? The really key issue is that you are evaluating the probability of a sustained and powerful impact of this work.
For training grants — and I think training grants are a little confusing, and there was a question about this earlier today. For training grants which are Fs or even career grants, the Ks, what the reviewers are supposed to think about is whether the research plan will provide the applicant with individualized and supervised experiences that will develop the research skills needed for his or her career.
Even though it seems as if what is being attended to is the skill set that you’re developing for your career, it always boils down to a compelling, feasible, strong research plan. Always, always, always.
It seems as though, in the training grants, reviewers are attending to different things, but in many ways — they attend to the training potential, in addition to the strength of the other components.
A strong research plan is an essential part of considering review of training and review of impact of this work.

What are some considerations? We’ve talked at length about the approach linking clearly to the theoretical and clinical questions. I’m going to do is give you a beautiful example of this in a few minutes.
Impact is actually a combination of all of the components we’re thinking about right now — significance, innovation, approach. Approach can be very heavily weighted in the impact score. In fact, even if this is a highly significant, highly innovative piece of work without difficulties with the experiments, it would completely lower the impact if people don’t believe you could do it.
Very often, difficulties with the conceptual background become really obvious in the development of the experiments. I often get really excited about a grant, and then I read the experiments and I’m like, they’re not really testing this. Avoiding problems with that conceptual framework — this beautiful linkage we’ve talked about — is crucial.

The statistical plan, including power analysis, is often talked about in the summary statement. I’m trying to draw on various components that I think show up a lot.
Preliminary data, even for an F31, are crucial. They might just be used to illustrate feasibility. In our speech group yesterday, we reviewed a grant that had this very cool synchrony analysis, — but including even one figure showing how they collected a feasibility figure from one subject, I think, would have very much clarified the analysis plan and how the data will be analyzed. Even for a very first F31 grant, feasibility data are absolutely critical.
Another consideration in my potpourri of considerations is reliability being included. We are working with humans, we are often working with disordered humans. To have reliable coding procedures, tests, fidelity of administration in an intervention study — you cannot cover everything in your six to twelve pages, but your reviewer has to be convinced that you know how to handle these issues.

In feasibility, these are issues that I find come up. Feasibility of recruiting participants is huge. Shelley mentioned this dynamic between the power problem and funding. If you cannot find 30 people with well-specified Broca’s aphasia, and you can’t convince people that’s believable, you’re in very big trouble, for example.
Ambitiousness of the work. The contingency of aims. I think we’re talked about that quite a bit.

Aims that are overly tied and contingent are a problem. But some other frequently occurring weaknesses are that aims are overly diffuse and unrelated. You’re looking for that happy medium, of the aims being really connected but not overly contingent. You don’t want to find that after six months, if specific aim one doesn’t work, you’re done. But you also don’t want them to be diffuse and unrelated.
We’ve talked about this one as well — and this really needs to be worked into the Approach section. The inclusion and integration of an appropriate scientific team.
I would add a mentor with appropriate experience, in the training grant world. If you have a wonderful mentor who is really equipped to mentor parts of your project, but you’re the first person they’ve ever mentored, for example, you may want a more experienced mentor — this kind of goes into that category.
If you’re applying a new statistic or a new methodology, you must integrate that consultant.
Include authentic pitfalls. It’s very easy to say this very global thing of what might go wrong. But you need pitfalls that demonstrate that you’re thinking this through. I’m going to give you an example of this in just a moment.

Sometimes you realize in your critiques that the reviewer misunderstood what you were doing. This I put on here because it happens to me a lot. I use methodologies that are really tied to a particular theory that happens to not be my theory. I have learned that it is my responsibility to be incredibly explicit about my theoretical perspective — to blame myself when the reviewers miss the boat here.
This is something reviewers do often — I’m a reviewer a lot and I know I misunderstand when somebody resubmits and explains it. But it’s their job to make it so that I don’t have to read it for nine hours to understand what they’re talking about.
I think we’ve talked a lot about the power of pictures, so I’m just going to zoom through this and the next slide.

Power Analysis
I’m going to give you one example — and this is thanks to Elena for this example — of where the power estimate should go. This gives one framework that deals with the issue of being incredibly concise and dealing with the page limits.

The power estimate can go in many sections. This gives you a sense of the flexibility of how you can construct your proposal. It can go with Preliminary Studies, with pilot data for each task, for example.
It can go with the Approach Section. It might be with your participants, where you are describing the number of your participants. If you are using a similar method, if similar effect sizes are predicted across the whole experiment — you can include your power analysis in that subject section.
Or it can go before each individual study, if your different studies really have different methodologies that are being applied.
Or you can do a Statistical Plan section.
I think I’ve done all of these, depending on what the grant is. The point of this example is that there is not a rule, except that it be included, and that it be included in a really accessible way, that is the most space efficient.

This is an example from Elena.
Studies involving children will use a minimum of 25 children per group (50 children total). Power calculations based on the most similar studies completed during the last grant cycle indicate that this N size should provide a minimum of 80% power to detect significant effects at p < .05.
So that’s her first power estimate. Then she has another group — but she is being so space efficient here.
Adult samples tend to show larger between-group effects for similar tasks, requiring fewer subjects.
So here’s how many we require for the adults. And then, finally:
Although these estimates are used for planning purposes, we routinely check effect sizes when approximately two thirds of the data have been collected so that data from additional subjects can be included if effect sizes are smaller than anticipated. Our recruitment sources (i.e., available school programs) are sufficiently large to allow this measure of flexibility.
Think of the number of things she’s demonstrated in this section. She is able to alleviate any concerns her reviewer might have about the power analysis and the ability to find participants. A lot of the feasibility issues are addressed in this very readable paragraph.

That’s one example, and on this slides there are some additional resources for thinking about this issue.
Example Approach

For this second example, I asked Larry Leonard and he kindly agreed to share a grant, this is actually an R21 that was recently funded. I think he is a master, and the best way to kick off this session is to look at a pretty masterful arrangement of the theory, the aims, the methods, and the pitfalls. Hopefully this brings it together and sends us off with a nice example as we look at each other’s grants.

I extracted this from his six-page R21 application.
Many common errors in SLI across different languages….can be logically related to an assumption of inappropriate extraction of nonfinite subject-verb sequences.
You’re going to see in a minute what it means, if you don’t know already.
There is now emerging evidence that children with SLI are, in fact, prone to extract nonfinite subject-verb sequences from larger structures in the input. However, the next crucial step for this proposal – demonstrating that this inappropriate extraction is related to a failure to grasp the structural dependencies in larger structures – has not yet been taken.
This gives theoretical depth — why there is a gap, what this proposal is going to do — in very few words.

Translational implications — this is for an NIDCD panel.
This perspective could lead to a wholly new approach to treatment. Specifically, intervention might be directed at comprehension, to help children learn the structural dependency between nonfinite sequences and early appearing finite verb information. A new approach is sorely needed, given that previous intervention attempts have produced only modest results at best.
Here is a big problem in the world of SLI. I might be able to solve it.

Then his Specific Aims.
Will typically developing children make use of early-appearing finite information in questions that serve as cues to information appearing later in the questions, while children with SLI fail to make use of this information?
So when kids when SLI say “dogs running” and omit that critical “are” does it have to do with how they are comprehending the bigger sentence? That’s what he’s trying to understand. He’s made that really clear.
Will children’s sensitivity or insensitivity to this early-appearing finite information serve as a significant predictor of their consistency/inconsistency in using the same tense/agreement forms in their own speech?
This has been a long-standing problem in SLI, and he has a new idea about it. Which is why it’s an R21.

So we’re going from the theory, to the aims, and now the specific analyses.
To address Specific Aim 1, we will compare the three groups of children on the looking-while-listening measures. First, we will examine the children’s mean RT in shifting gaze from distractor to target using an ANOVA with participant group as a between-subjects variable. We expect a significant interaction, with the TD-A and TD-Y groups showing faster RTs in the finite-cue condition than in the no-finite cue condition, whereas the children with SLI will show no RT difference between the two cue conditions.
Incredibly clear, we know how this is going to come out — or how he predicts it will.

For the second analysis, using mean percentage of looking at the target in the pre-noun time window, we expect a similar interaction. Judging from the effect sizes in our pilot work, we have determined that an n of 18 for each group in each experiment will have power greater than .80 at p < .05.
And there is the power analysis — it’s all there.

Now, the last piece is to move to complex findings and caveats. He has a very sophisticated and precise way of saying, “however, I might be wrong.”
To address Specific Aim 2, we will use regression analyses……we ask if the children’s mean percentage of (pre-noun) looking to the target in the finite-cue condition serves as a predictor of the child’s use of copula or auxiliary forms.
So, are they analyzing that first word driving their responses, or might it be something else?

Here’s alternate predictions, pitfalls, and caveats in such a slick way.
We will also include the children’s scores on the Sentence Structure subtest of the CELF-P2 as well as the children’s digit span scores. The former serves as a general language comprehension measure that does not focus on the kinds of structural ties hypothesized to be related to the children’s inconsistent use of copula and auxiliary forms.
The latter (digit span) serves as a measure of verbal short-term memory. This measure is included because a failure to grasp the structural ties between an early appearing finite form and a later appearing noun may be due to a failure to retain the finite information.
So he has the core hypothesis, but also allows for alternate possibilities — maybe comprehension, or maybe short-term memory. These are how the data will inform his hypotheses, here are the caveats.
And finally, we’re really looking to see if these looking measures predict unique variance, or if these other measures are really explaining the variability we observe in these kids.
In this analysis we seek to determine if our looking measure predicts unique variance in the children’s copula and auxiliary use scores over and beyond the variance explained by the Sentence Structure and digit span scores.

When I’m getting ready to write, I look at this kind of example and say, “Can I make things hang together like this?” I know it’s weird to just read it, but I wanted to kick this off by looking at this example.
It’s a really standard design, but it includes all of the crucial components.
Final Thought
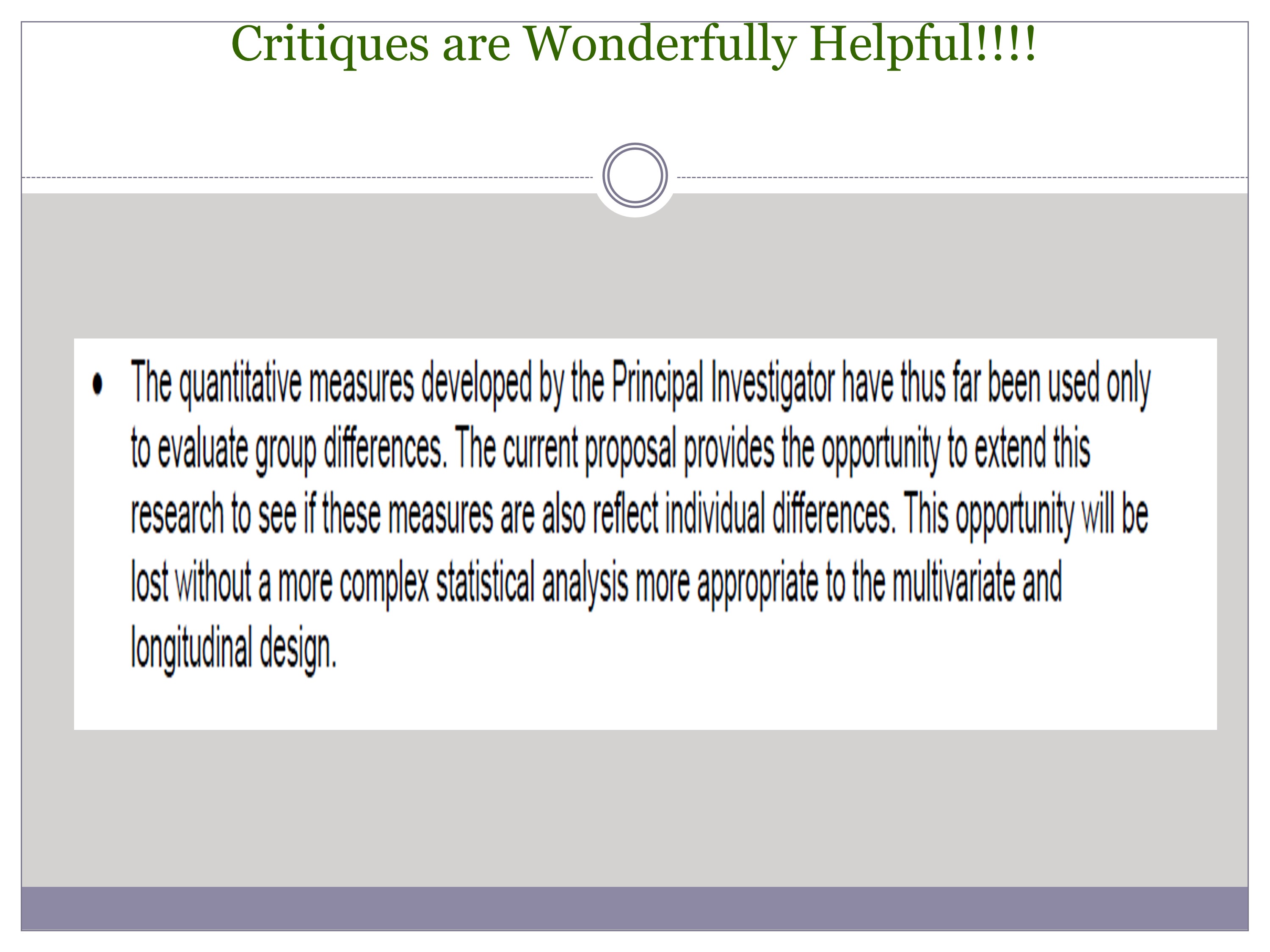
I have exactly one more slide here. This is approach-related. And we’ve talked a lot about critiques being really important — and critiques being very often focused on approach, in my experience.
This is actually from my current grant that was funded, and this was the round that it was funded on. But I got this beautiful comment. You can tell this is extracted from my critique because you can’t read it, but it says:
The quantitative measures developed by the Principal Investigator have thus far been used only to evaluate group differences. The current proposal provides the opportunity to extend this research to see if these measures also reflect individual differences. This opportunity will be lost without a more complex statistical analysis more appropriate to the multivariate and longitudinal design.
We were just talking about this issue, where I planned my standard ANOVA, and my reviewer said, “You could make this so much better.” And I did. I went and got a stats consultant. This was a funded proposal. This is a last little message about what the reviewers put into the process.

